Processing different data types#
In this chapter, you will learn how to process different types of data using n8n core nodes.
HTML and XML data#
You're most likely familiar with HTML and XML.
HTML vs. XML
HTML is a markup language used to describe the structure and semantics of a web page. XML looks similar to HTML, but the tag names are different, as they describe the kind of data they hold.
If you need to process HTML or XML data in your n8n workflows, use the HTML Extract node or XML node.
The HTML Extract node allows you to extract HTML content of a webpage, by referencing CSS selectors. This is useful if you want to collect structured information from a website (web-scraping).
Exercise#
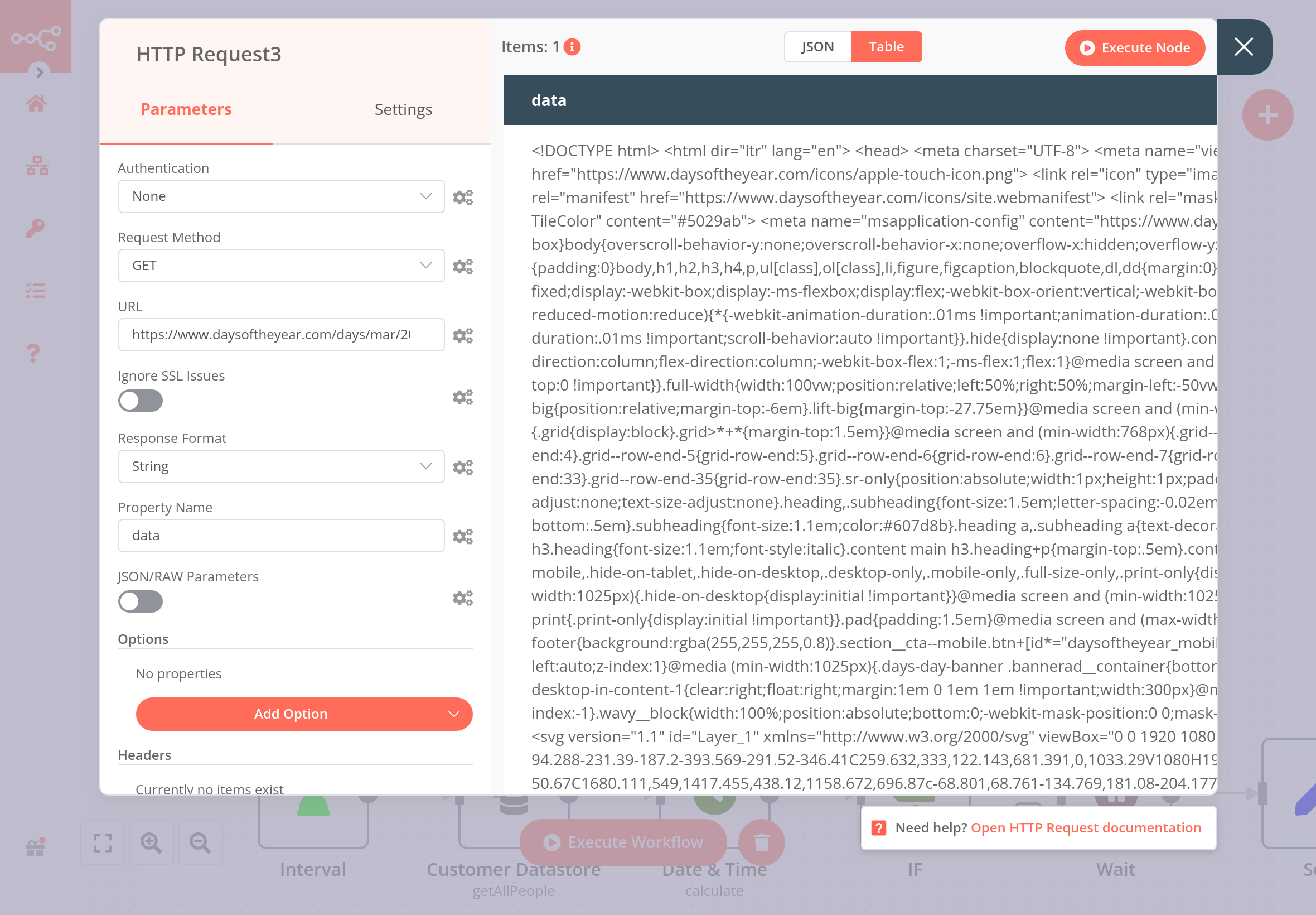
Use the HTTP Request node to make a GET request to the URL https://www.daysoftheyear.com/days/mar/2022/. Then, connect an HTML Extract node and configure it to extract the date of the returned events.
Show me the solution
Configure the HTTP Request node with the following parameters:
- Authentication: None
- Request Method: GET
- URL: https://www.daysoftheyear.com/days/mar/2022/
The result should look like this:
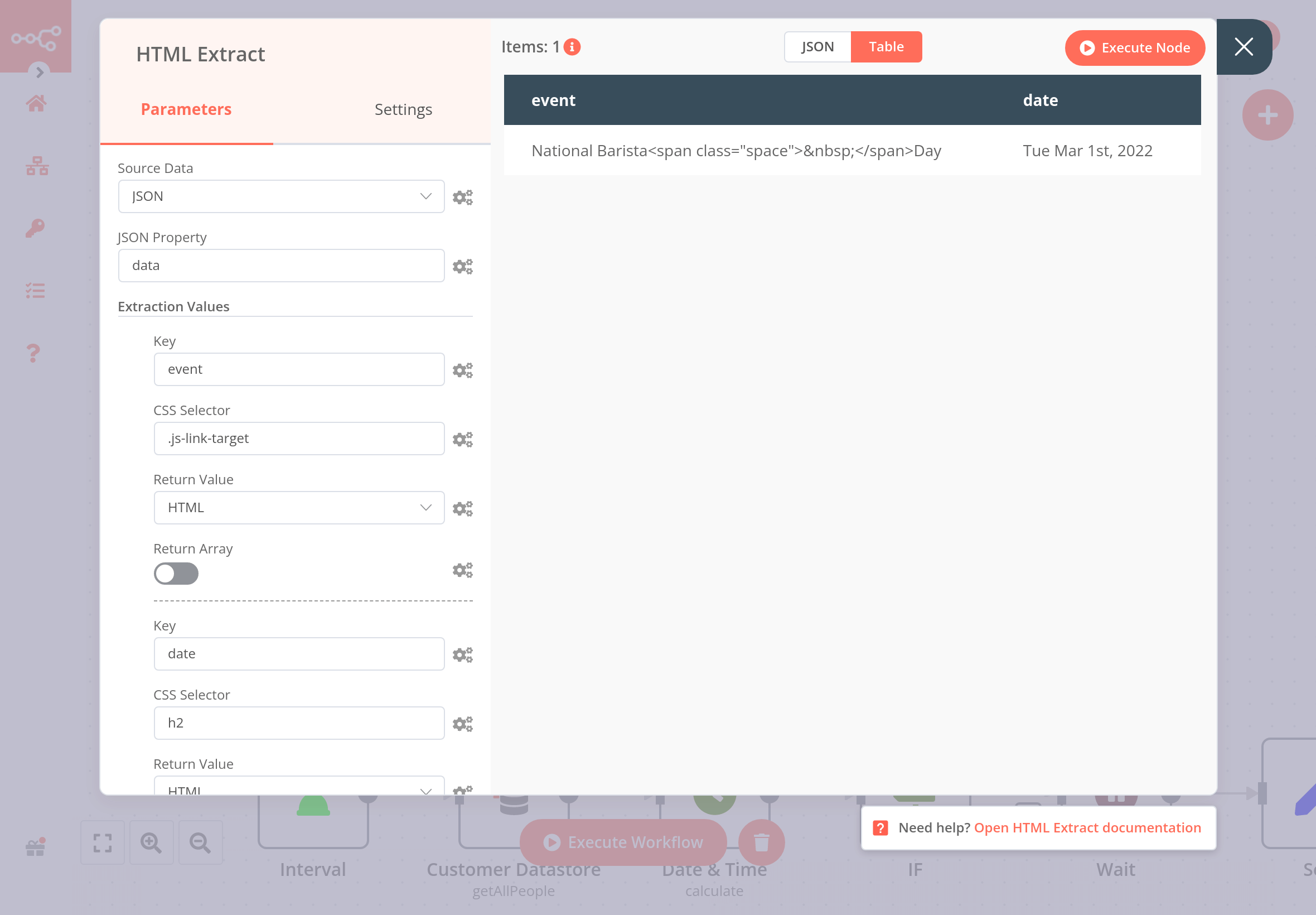
Connect an HTML Extract node to the HTTP Request node and configure the former's parameters:
- Source Data: JSON
- JSON Property: data
- Extraction Values:
- Key: event
- CSS Selector: .js-link-target
- Return Value: HTML
You can add more values to extract more data.
The result should look like this:
The XML node allows you to convert XML to JSON and JSON to XML. This operation is useful if you work with different web services that use either XML or JSON, and need to get and submit data between them in the two formats.
Exercise#
In a previous exercise, you used an HTTP Request node to make a request to an API. Now, use the XML node to convert the JSON output to XML.
Show me the solution
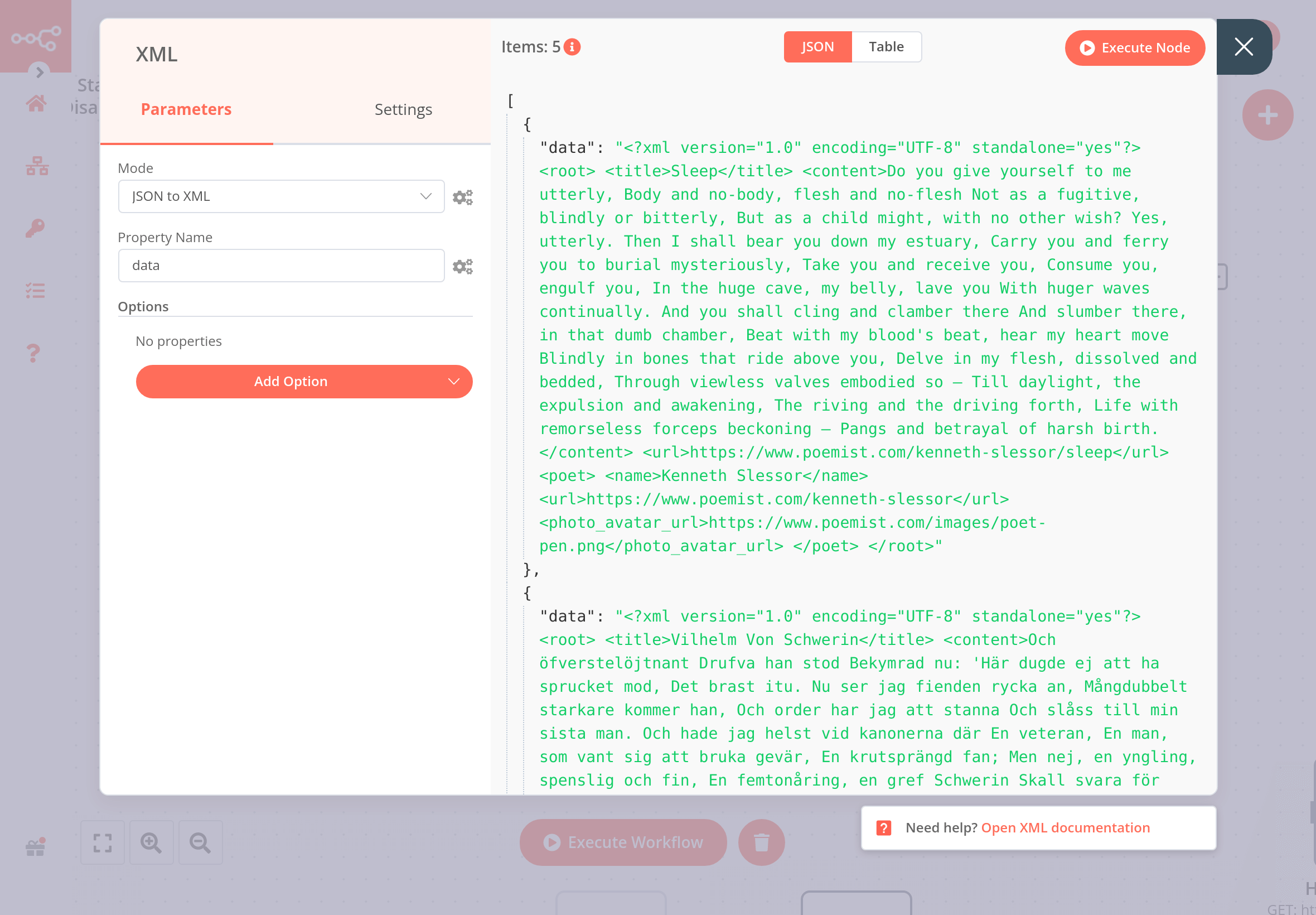
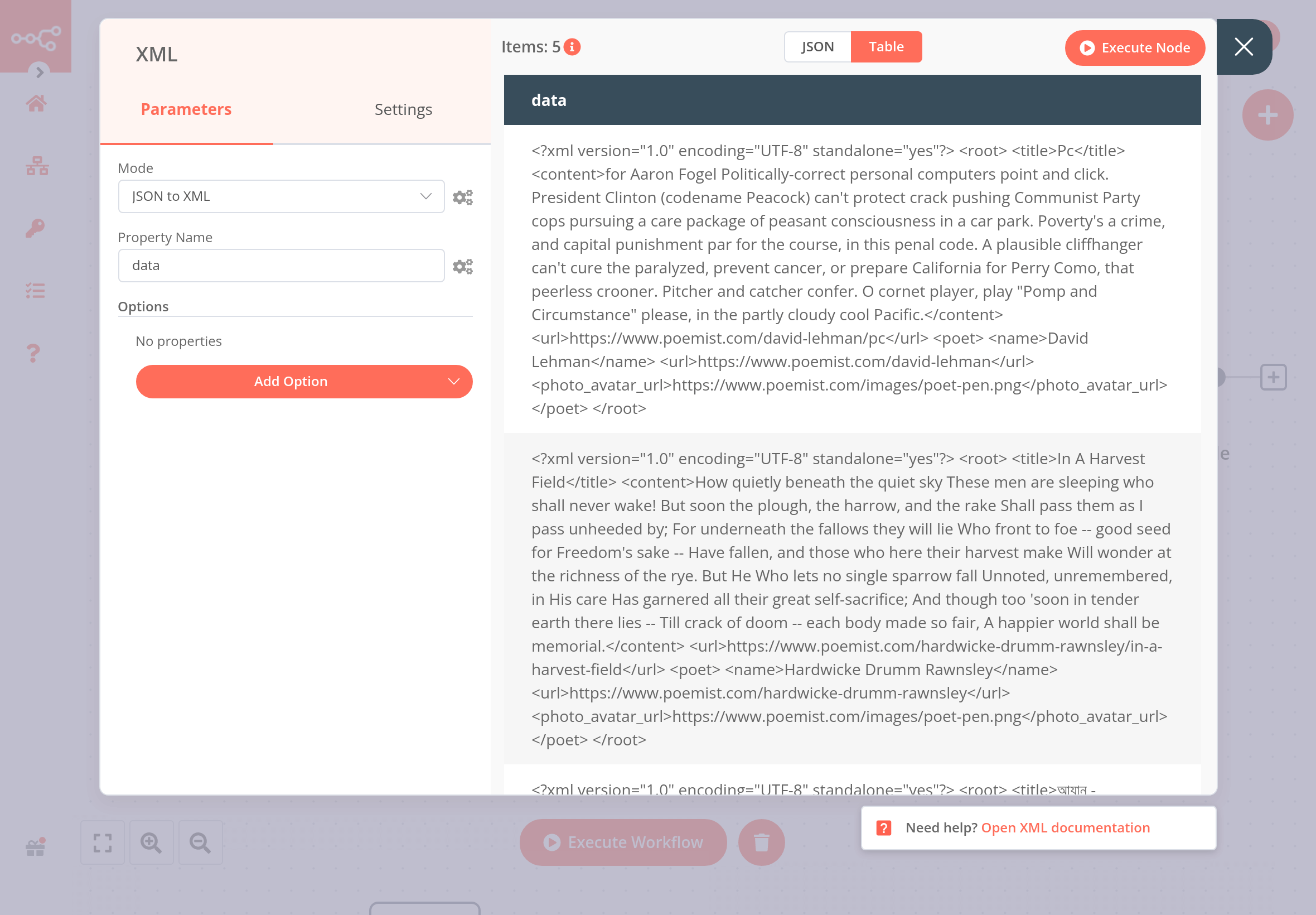
Get data from the Poemist API using the HTTP Request node and connect an XML node to it with the following parameters:
- Mode: JSON to XML
- Property name: data
The result should look like this:
To transform data the other way around, select the mode XML to JSON.
Date, time, and interval data#
Date and time data types include DATE, TIME, DATETIME, TIMESTAMP, and YEAR. The dates and times can be passed in different formats, for example:
DATE: March 29 2022, 29-03-2022, 2022/03/29TIME: 08:30:00, 8:30, 20:30DATETIME: 2022/03/29 08:30:00TIMESTAMP: 1616108400 (Unix timestamp), 1616108400000 (Unix ms timestamp)YEAR: 2022, 22
If you need to convert date and time data to different formats, and calculate dates, use the Date & Time node.
You can also schedule workflows to run at a specific time, interval, or duration, using the two trigger nodes:
- Schedule Trigger triggers the workflow at fixed dates and/or times (for example, every Monday at 9am).
- Interval node} triggers the workflow in regular intervals of time (for example, every 10 minutes).
In some cases, you might need to pause the workflow execution. This might be necessary, for example, if you know that a service doesn't process the data instantly or it is generally slower, so you don't want the incomplete data to be passed to the next node. In this case, you can use the Wait node after the node that you want to delay. The Wait node pauses the workflow execution and resumes it at a specific time, after a time interval, or on a webhook call.
Exercise#
Build a workflow that adds five days to an input date. Then, if the calculated date occurred after today, the workflow waits 1 minute before setting the calculated date as a value. The workflow should be triggered every 30 minutes.
Show me the solution
You can build this workflow using the data from the Customer Datastore node, the three nodes for managing date and time, an IF node for conditional routing, and a Set node for setting the new calculated date. The workflow looks like this:
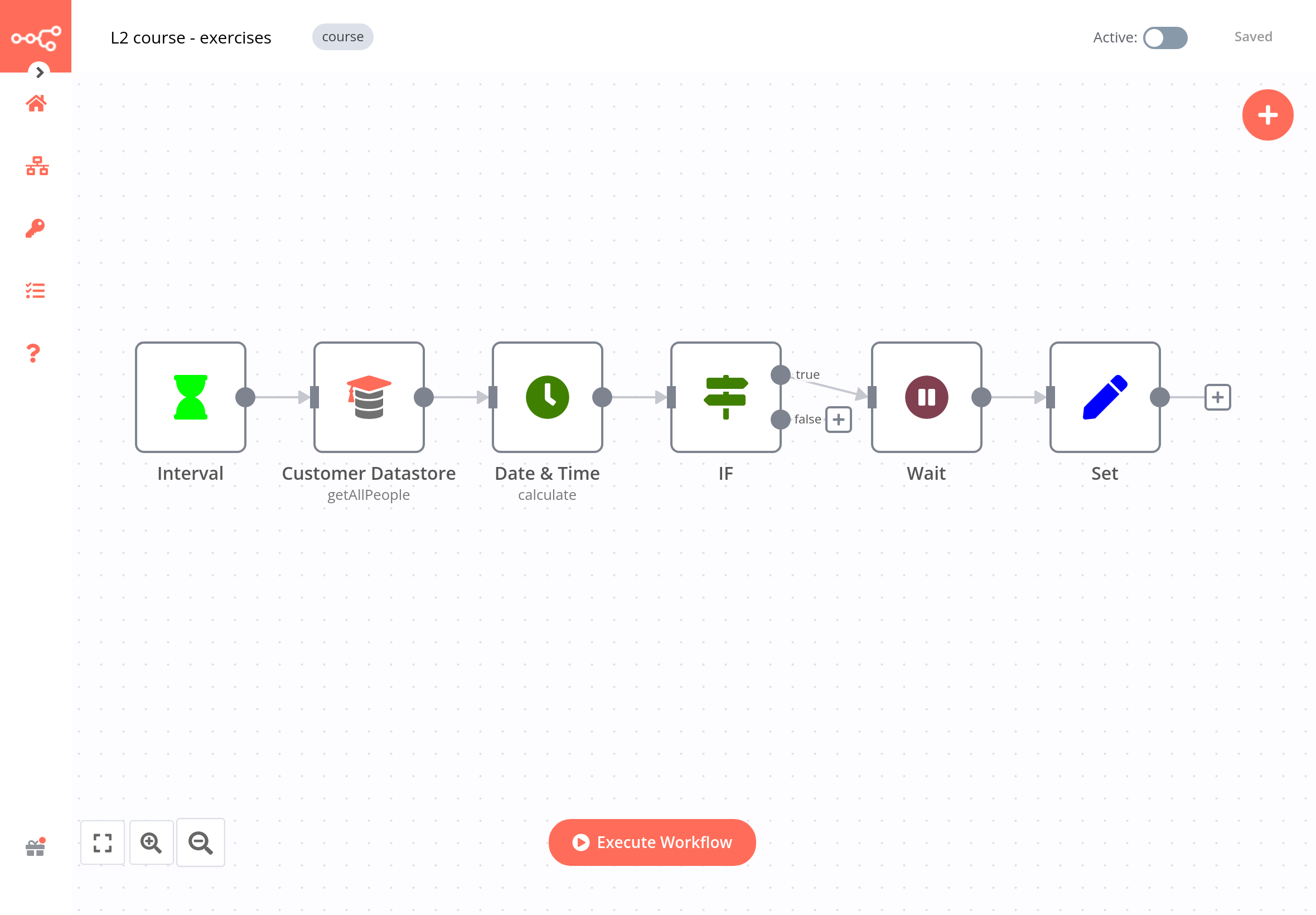
To check the configuration of each node, you can copy the JSON code of this workflow and paste it in your Editor UI.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 | |
Binary data#
So far, you have mainly worked with text data. But what if you want to process data that is not text? For example, images or PDF files. This is binary data, as it is represented in the binary numeral system. In this form, binary data doesn't offer you useful information, so it needs to be converted into a readable form.
In n8n, you can process binary data with the following nodes:
- Move Binary Data node to move data between binary and JSON properties.
- Read Binary File node to read a file from the host machine that runs n8n.
- Read Binary Files to read multiple files from the host machine that runs n8n.
- Write Binary File to write a file to the host machine that runs n8n.
- Spreadsheet File node to read from or write to spreadsheet files of different formats (for example, CSV, XLSX).
To read or write a binary file, you need to write the path (location) of the file in the node's File Name parameter.
Naming the right path
The file path looks slightly different on n8n cloud compared to desktop or self-hosted:
- n8n desktop and self-hosted:
./Documents/my_file.json - n8n cloud:
/home/node/.n8n/my_file.json
Exercise#
Make an HTTP request to get this PDF file: https://media.kaspersky.com/pdf/Kaspersky_Lab_Whitepaper_Anti_blocker.pdf. Then, use the Move Binary Data node to convert the file from binary to JSON, with base64 encoding.
Show me the solution
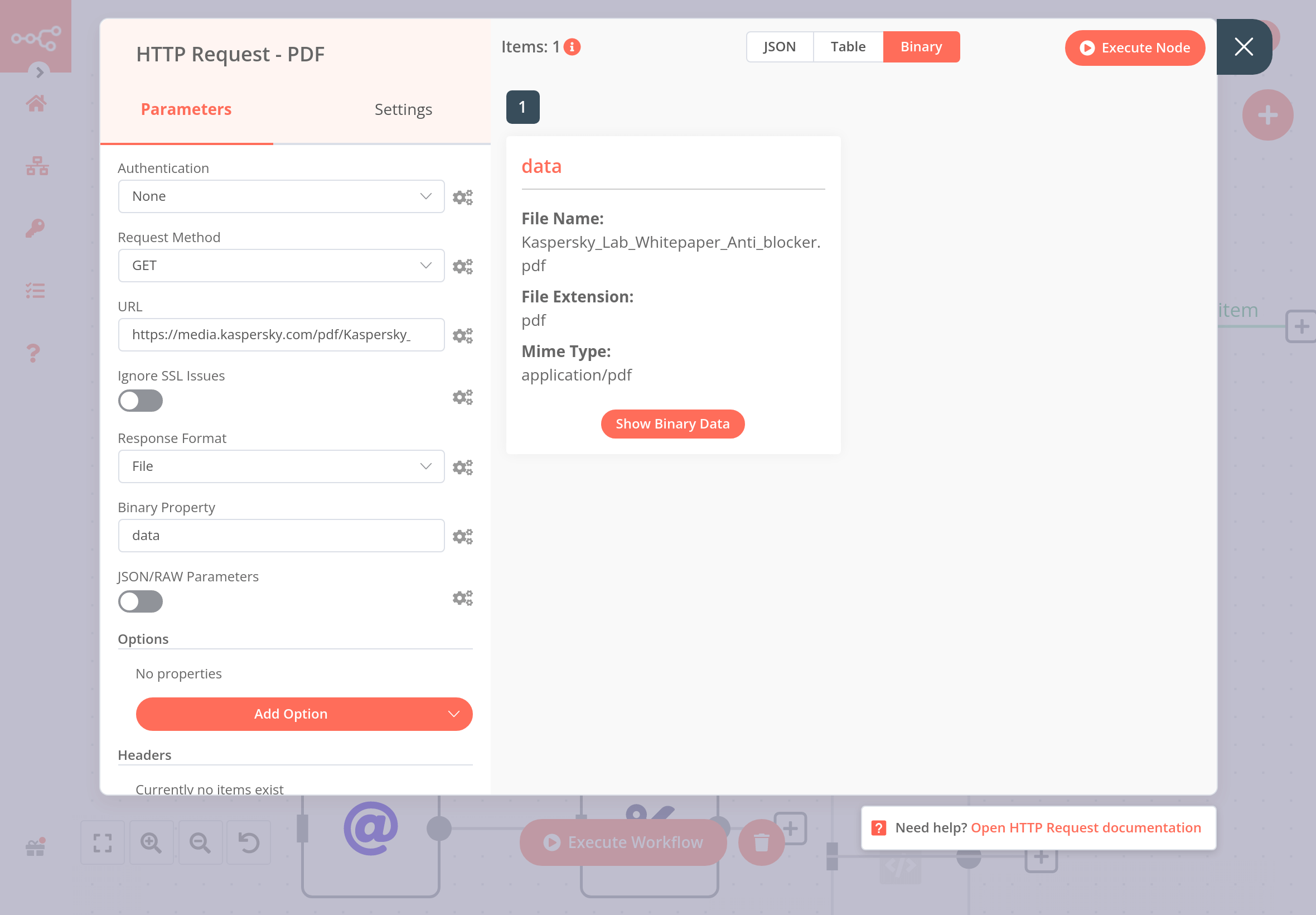
In the HTTP Request node, you should see the PDF file in JSON, Table, and Binary view, like this:
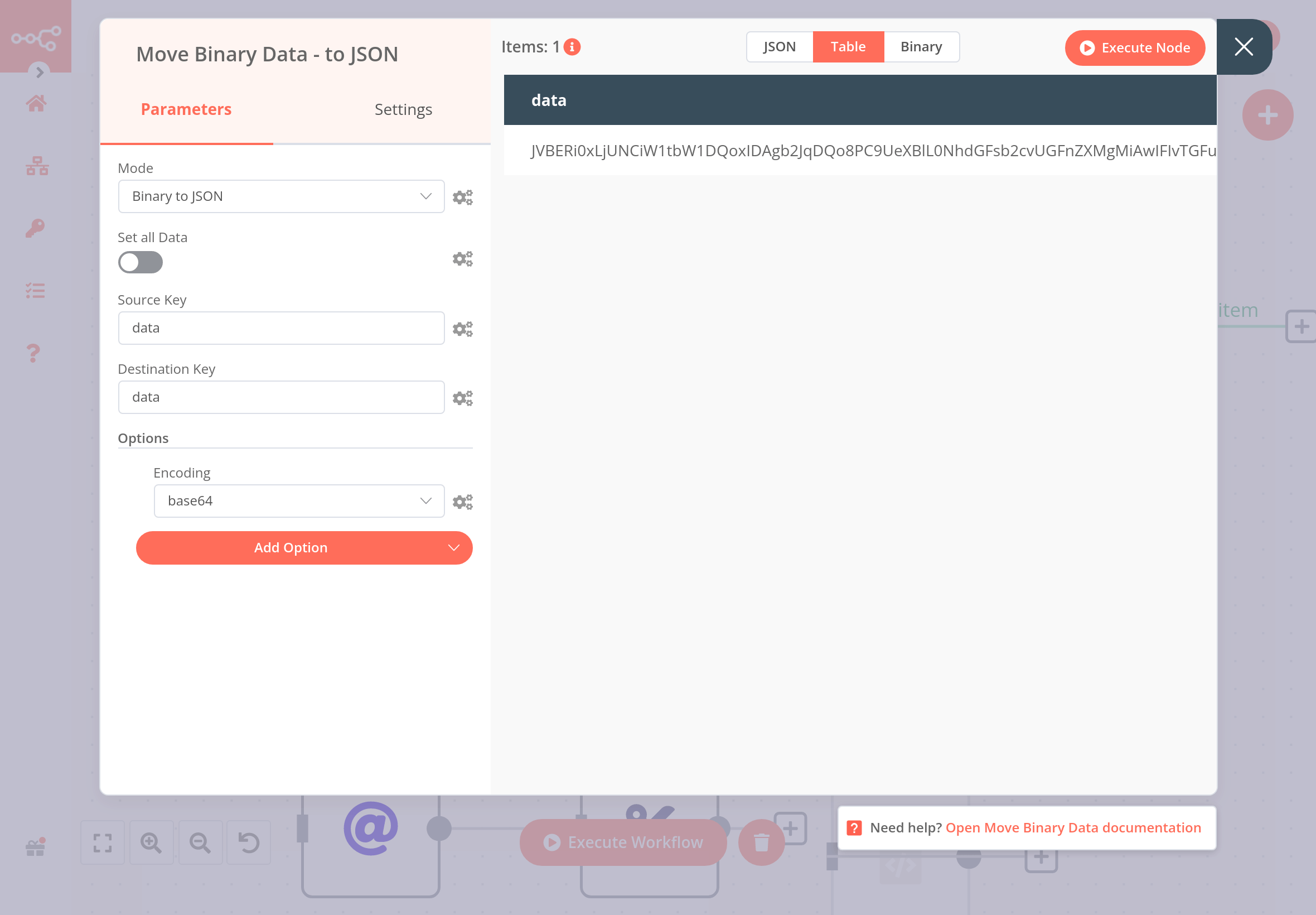
When you convert the PDF from binary to JSON with base64 encoding using the Move Binary Data node, the result should look like this:
To check the configuration of the nodes, you can copy-paste the JSON code of the workflow:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | |
Exercise#
Make an HTTP request to the Poemist API https://www.poemist.com/api/v1/randompoems and move the returned data from JSON to binary. Then, write the new binary data to a file. Finally, to check that it worked out, read the generated binary file referencing it with an expression in the node.
Show me the solution
The workflow for this exercise looks like this:
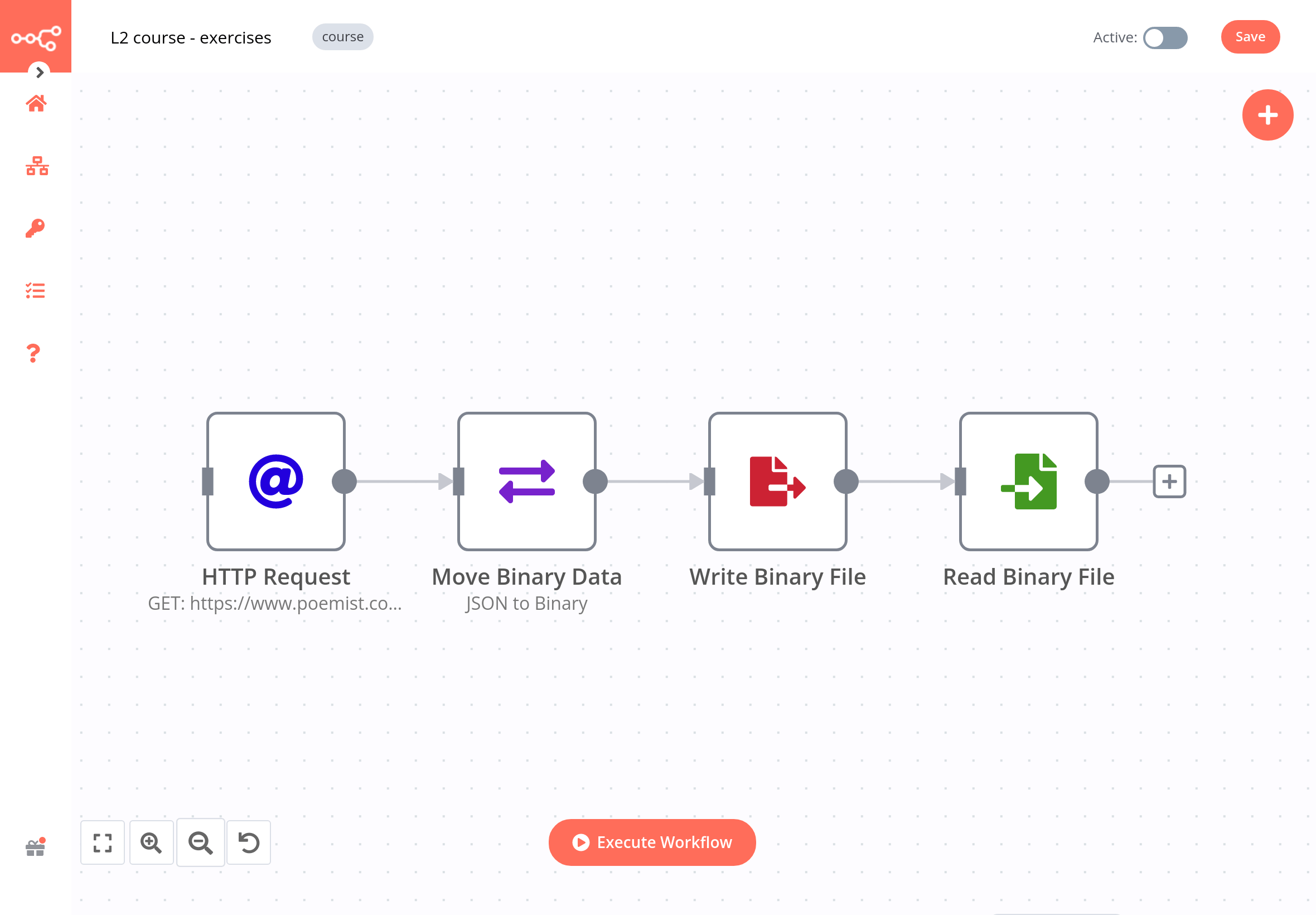
To check the configuration of the nodes, you can copy-paste the JSON code of the workflow:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 | |